2 критерия. П.2
Лекция 6. Анализ двух выборок
6.1 Параметрические критерии. 1
6.1.2 Критерий Стьюдента (t -критерий) 2
6.1.3 F - критерий Фишера. 6
6.2 Непараметрические критерии. 7
6.2.1 Критерий знаков (G -критерий) 7
Следующей задачей статистического анализа, решаемой после определения основных (выборочных) характеристик и анализа одной выборки, является совместный анализ нескольких выборок. Важнейшим вопросом, возникающем при анализе двух выборок, является вопрос о наличии различий между выборками. Обычно для этого проводят проверку статистических гипотез о принадлежности обеих выборок одной генеральной совокупности или о равенстве средних.
Если вид распределения или функция распределения выборки нам заданы, то в этом случае задача оценки различий двух групп независимых наблюдений может решаться с использованием параметрических критериев статистики: либо критерия Стьюдента (t ), если сравнение выборок ведется по средним значениям (X и У), либо с использованием критерия Фишера (F ), если сравнение выборок ведется по их дисперсиям.
Использование параметрических критериев статистики без предварительной проверки вида распределения может привести к определенным ошибкам в ходе проверки рабочей гипотезы.
Для преодоления указанных трудностей в практике педагогических исследований следует использовать непараметрические критерии статистики , такие, как критерий знаков, двухвыборочный критерий Вилкоксона, критерий Ван дер Вардена, критерий Спирмена, выбор которых, хотя и не требует большого числа членов выборки и знаний, вида распределения, но все же зависит от целого ряда условий.
Непараметрические критерии статистики - свободны от допущения о законе распределения выборок и базируются на предположении о независимости наблюдений.
6.1 Параметрические критерии
В группу параметрических критериев методов математической статистики входят методы для вычисления описательных статистик, построения графиков на нормальность распределения, проверка гипотез о принадлежности двух выборок одной совокупности. Эти методы основываются на предположении о том, что распределение выборок подчиняется нормальному (гауссовому) закону распределения. Среди параметрических критериев статистики нами будут рассмотрены критерий Стьюдента и Фишера.
6.1.1 Методы проверки выборки на нормальность
Чтобы определить,имеем ли мы дело с нормальным распределением, можно применять следующие методы:
1) в пределах осей можно нарисовать полигон частоты (эмпирическую функцию распределения) и кривую нормального распределения на основе данных исследования. Исследуя формы кривой нормального распределения и графика эмпирической функции распределения, можно выяснить те параметры, которыми последняя кривая отличается от первой;
2) вычисляется среднее, медиана и мода и на основе этого определяется отклонение от нормального распределения. Если мода, медиана и среднее арифметическое друг от другазначительно не отличаются, мы имеем дело с нормальным распределением. Если медиана значительно отличается от среднего, то мы имеем дело с асимметричной выборкой.
3) эксцесс кривой распределения должен быть равен 0. Кривыесположительнымэксцессомзначительновертикальнее кривой нормального распределения. Кривые с отрицательным эксцессом являются более покатистыми по сравнению с кривой нормального распределения;
4) послеопределения среднего значения распределения частоты и стандартного oтклонения находят следующие четыре интервала распределения сравнивают их с действительными даннымиряда:
а) - к интервалу должно относиться около 25% частоты совокупности,
б) - к интервалу должно относиться около 50% частоты совокупности,
в) - к интервалу должно относиться около 75% частоты совокупности,
г) - к интервалу должно относиться около 100% частоты совокупности.
6.1.2 Критерий Стьюдента ( t-критерий)
Критерий позволяет найти вероятность того, что оба средних значения в выборке относятся к одной и той же совокупности. Данный критерий наиболее часто используется для проверки гипотезы: «Средние двух выборок относятся к одной и той же совокупности».
При использовании критерия можно выделить два случая. В первом случае его применяют для проверки гипотезы о равенстве генеральных средних двух независимых , несвязанных выборок (так называемый двухвыборочный t-критерий ). В этом случае есть контрольная группа и экспериментальная (опытная) группа, количество испытуемых в группах может быть различно.
Во втором случае, когда одна и та же группа объектов порождает числовой материал для проверки гипотез о средних, используется так называемый парный t-критерий . Выборки при этом называют зависимыми , связанными .
а) случай независимых выборок
Статистика критерия для случая несвязанных, независимых выборок равна:
где , - средние арифметические в экспериментальной и контрольной группах,
Стандартная ошибка разности средних арифметических. Находится из формулы:
![]() ,(2)
,(2)
где n 1 и n 2 соответственно величины первой и второй выборки.
Если n 1 =n 2 , то стандартная ошибка разности средних арифметических будет считаться по формуле:
 (3)
(3)
где n величина выборки.
Подсчет числа степеней свободы осуществляется по формуле:
k = n 1 + n 2 – 2.(4)
При численном равенстве выборок k = 2 n - 2.
Далее необходимо сравнить полученное
значение t
эмп
с теоретическим значением t-распределения
Стьюдента (см. приложение к учебникам
статистики). Если t
эмп Рассмотрим
пример использования
t
-критерия Стьюдента
для несвязных и неравных по численности
выборок.
Пример 1
.
В двух группах учащихся -
экспериментальной и контрольной -
получены следующие результаты по учебному
предмету (тестовые баллы; см. табл. 1). Таблица 1. Результаты
эксперимента Первая
группа (экспериментальная) N
1 =11
человек Вторая
группа (контрольная) N
2 =9
человек 121413161191315151814 Общее количество членов выборки: n
1 =11, n
2 =9. Расчет средних арифметических: Х ср =13,636;
Y
ср =9,444 Стандартное отклонение: s
x =2,460;
s
y
=2,186
По формуле (2) рассчитываем
стандартную ошибку разности
арифметических средних:
Считаем статистику
критерия:
Сравниваем
полученное в эксперименте значение t с
табличным значением с учетом степеней
свободы, равных по формуле (4) числу
испытуемых минус два (18). Табличное значение t крит
равняется 2,1 при допущении возможности
риска сделать ошибочное суждение в пяти
случаях из ста (уровень значимости=5 % или
0,05). Если полученное в
эксперименте эмпирическое значение t превышает
табличное, то есть основания принять
альтернативную гипотезу (H 1) о том, что
учащиеся экспериментальной группы
показывают в среднем более высокий уровень
знаний. В эксперименте t=3,981, табличное t=2,10,
3,981>2,10, откуда следует вывод о
преимуществе экспериментального обучения. Здесь могут возникнуть
такие вопросы
: 1. Что если полученное в
опыте значение t окажется меньше табличного?
Тогда надо принять нулевую гипотезу. 2. Доказано ли преимущество
экспериментального метода? Не столько
доказано, сколько показано, потому что с
самого начала допускается риск ошибиться в
пяти случаях из ста (р=0,05). Наш эксперимент
мог быть одним из этих пяти случаев. Но 95%
возможных случаев говорит в пользу
альтернативной гипотезы, а это достаточно
убедительный аргумент в статистическом
доказательстве. 3. Что если в контрольной
группе результаты окажутся выше, чем в
экспериментальной? Поменяем, например,
местами, сделав
средней арифметической экспериментальной
группы, a
- контрольной:
Отсюда следует
вывод, что новый метод пока не проявил себя
с хорошей стороны по разным, возможно, причинам.
Поскольку абсолютное значение 3,9811>2,1,
принимается вторая альтернативная
гипотеза (Н 2) о преимуществе
традиционного метода. В случае связанных выборок с равным
числом измерений в каждой можно
использовать более простую формулу t-критерия
Стьюдента. Вычисление значения t осуществляется по
формуле: где
- разности между соответствующими
значениями переменной X и переменной У, а d
- среднее этих разностей; Sd вычисляется по следующей формуле:
Число степеней свободы k
определяется по формуле k=n
-1.
Рассмотрим пример использования t
-критерия
Стьюдента для связных и, очевидно, равных по
численности выборок. Если t
эмп Пример 2
.
Изучался уровень ориентации учащихся на
художественно-эстетические ценности. С
целью активизации формирования этой
ориентации в экспериментальной группе
проводились беседы, выставки детских
рисунков, были организованы посещения
музеев и картинных галерей, проведены
встречи с музыкантами, художниками и др.
Закономерно встает вопрос: какова
эффективность проведенной работы? С целью
проверки эффективности этой работы до
начала эксперимента и после давался тест.
Из методических соображений в таблице 2
приводятся результаты небольшого числа
испытуемых. Таблица 2. Результаты
эксперимента Ученики
(n
=10
)
Баллы
Вспомогательные
расчеты
до
начала эксперимента (Х)
в
конце
эксперимента
(У)
d
d
2
Иванов
Новиков
Сидоров
Пирогов
Агапов
Суворов
Рыжиков
Серов
Топоров
Быстров
Среднее
14,8
21,1
Вначале произведем расчет
по формуле:
Затем применим формулу (6), получим: И, наконец, следует
применить формулу (5). Получим:
Число степеней свободы: k
=10-1=9
и по таблице Приложения 1 находим t крит
=2.262, экспериментальное t=6,678, откуда следует
возможность принятия альтернативной
гипотезы (H 1) о достоверных различиях
средних арифметических, т. е. делается вывод
об эффективности экспериментального
воздействия. В терминах статистических гипотез
полученный результат будет звучать так: на
5% уровне гипотеза Н 0 отклоняется и
принимается гипотеза Н 1 . Критерий Фишера
позволяет
сравнивать величины выборочных дисперсий
двух независимых выборок. Для вычисления F эмп
нужно найти отношение дисперсий двух
выборок, причем так, чтобы большая по
величине дисперсия находилась бы в
числителе, а меньшая – в знаменателе.
Формула вычисления критерия Фишера такова: где
- дисперсии первой и второй выборки
соответственно. Так как, согласно условию критерия,
величина числителя должна быть больше или
равна величине знаменателя, то значение F эмп
всегда будет больше или равно единице. Число степеней свободы определяется
также просто: k
1 =n l
- 1
для первой выборки (т.е. для той
выборки, величина дисперсии которой больше)
и k
2 =n
2
- 1
для второй выборки. В Приложении 1 критические значения
критерия Фишера находятся по величинам k
1
(верхняя строчка таблицы) и k
2
(левый столбец таблицы). Если t
эмп >t
крит,
то нулевая гипотеза принимается, в
противном случае принимается
альтернативная. Пример 3.
В двух третьих классах
проводилось тестирование умственного
развития по тесту ТУРМШ десяти учащихся.
Полученные значения величин средних
достоверно не различались, однако
психолога интересует вопрос - есть ли
различия в степени однородности
показателей умственного развития между
классами. Решение. Для критерия Фишера необходимо
сравнить дисперсии тестовых оценок в
обоих классах. Результаты тестирования
представлены в таблице: Таблица 3. №№ учащихся
Первый класс
Второй класс
Суммы
Среднее
60,6
63,6
Рассчитав дисперсии для переменных X и Y,
получаем: s
x
2 =572,83;
s
y
2 =174,04
Тогда по формуле (8) для расчета по F
критерию Фишера находим:
По таблице из Приложения 1 для F
критерия при степенях свободы в
обоих случаях равных k
=10
- 1 = 9 находим F
крит =3,18
(<3.29), следовательно, в терминах
статистических гипотез можно утверждать,
что Н 0 (гипотеза о сходстве) может быть
отвергнута на уровне 5%, а принимается в этом
случае гипотеза Н 1 . Иc
следователь
может утверждать, что по степени
однородности такого показателя, как
умственное развитие, имеется различие
между выборками из двух классов. Сравнивая
на глазок (по процентным соотношениям)
результаты до и после какого-либо
воздействия, исследователь приходит к
заключению, что если наблюдаются различия,
то имеет место различие в сравниваемых
выборках. Подобный подход категорически
неприемлем, так как для процентов нельзя
определить уровень достоверности в
различиях. Проценты, взятые сами по себе, не
дают возможности делать статистически
достоверные выводы. Чтобы доказать
эффективность какого-либо воздействия,
необходимо выявить статистически значимую
тенденцию в смещении (сдвиге) показателей.
Для решения подобных задач исследователь
может использовать ряд критериев различия.Ниже будет рассмотрены
непараметрические критерии: критерий
знаков и критерий хи-квадрат.
Критерий
предназначен для сравнения состояния
некоторого свойства у членов двух зависимых
выборок
на основе измерений, сделанных
по шкале не ниже ранговой.
Имеется
две серии наблюдений над случайными
переменными
X
и У, полученные при рассмотрении
двух зависимых выборок
. На их основе
составлено N
пар
вида (х
i
, у
i
),
где х
i
, у
i
- результаты двукратного
измерения одного и того же свойства у
одного и того же объекта.
В
педагогических исследованиях объектами
изучения могут служить учащиеся, учителя,
администрация школ. При этом х
i
, у
i
могут быть, например, балловыми
оценками, выставленными учителем за
двукратное выполнение одной и той же или
различных работ одной и той же группой
учащихся до и после применения некоторого
педагогическою средства.
Элементы
каждой пары х
i
, у
i
сравниваются между собой по
величине, и паре присваивается знак «+»
,
если х
i
< у
i
, знак «-»
, если х
i
> у
i
и «0»
,
если х
i
= у
i
.
Нулевая
гипотеза
формулируются следующим образом: в
состоянии изучаемого свойства нет значимых
различий при первичном и вторичном
измерениях. Альтернативная гипотеза:
законы распределения величин
X
и У различны, т. е. состояния
изучаемого свойства существенно различны
в одной и той же совокупности при первичном
и вторичном измерениях этого свойства.
Статистика
критерия
(Т)
определяется следующим образом:
допустим,
что из
N
пар (х, у,)
нашлось
несколько пар, в которых значения
х
i
и
у
i
равны. Такие пары обозначаются
знаком «0» и при подсчете значения величины
Т
не учитываются.
Предположим, что за вычетом из числа N
числа пар, обозначенных знаком «0»,
осталось всего
n
пар.
Среди оставшихся
n
пар подсчитаем число пар,
обозначенных знаком «-», т.е, пары, в которых
x i
<
y i
.
Значение величины Т
и равно числу пар со знаком минус.
Нулевая гипотеза
принимается на
уровне
значимости 0,05, если наблюдаемое значение
T
<
n
-
t a
,
где значение
n
-
t a
определяется
из статистических таблиц для критерия
знаков Приложения 2.
Пример
4.
Учащиеся выполняли контрольную работу,
направленную на проверку усвоения
некоторого понятия. Пятнадцати учащимся
затем предложили электронное пособие,
составленное с целью формирования данного
понятия у учащихся с низким уровнем
обучаемости. После изучения пособия
учащиеся снова выполняли ту же
контрольного работу, которая оценивалась
по пятибалльной системе.
Результаты
двукратного выполнения работы
представляют измерения по шкале порядка (пятибалльная
шкала). В этих условиях возможно
применение знакового критерия для
выявления тенденции изменения состояния
знаний учащихся после изучения пособия, так
как выполняются все допущения этого
критерия.
Результаты
двукратного выполнения работы (в баллах) 15
учащимися запишем в форме таблицы (см. табл.
1).
Таблица
4.
Учащиеся (№) Первое выполнение Второе выполнение Знак разности отметок Проверяется
гипотеза
H
0
:
состояние знаний учащихся не повысилось
после изучения пособия. Альтернативная
гипотеза:
состояние
знаний учащихся повысилось после изучения
пособия.
Подсчитаем
значение статистики критерия Т равное
числу положительных разностей отметок, полученных
учащимися. Согласно данным табл. 4 Т=10, n=12.
Для
определения критических значений
статистики критерия n-ta используем табл.
Приложения 2. Для уровня значимости а = 0,05
при
n
=12
значение n-ta=9. Следовательно выполняется
неравенство Т> n-ta (10>9). Поэтому в
соответствии с правилом принятия решения
нулевая гипотеза отклоняется на уровне
значимости 0,05 и принимается
альтернативная гипотеза, что позволяет
сделать вывод об улучшении знаний учащихся
после самостоятельного изучения пособия.
Пример
5.
Предполагается, что изучение курса
математики способствует формированию у
учащихся одного из приемов логического
мышления (например, приема обобщения) даже в
том случае, если его формирование не
проводится целенаправленно. Для проверки
этого предположения был проведен следующий
эксперимент.
Учащимся
VII
класса было предложено 5 задач,
решение которых основано на использовании
данного приема мышления. Считалось, что
учащийся владеет этим приемом, если он дает
верный ответ на 3 и более задачи.
Была
разработана следующая шкала измерений:
верно решена 1 или 2 задачи -
оценка «0»; верно решено 3 задачи -
оценка «1»; верно решено 4 задачи- оценка «2»;
верно решено 5 задач - оценка «3».
Работа
проводилась дважды: в конце сентября и
конце мая следующего года. Ее писали 35 одних
и тех же учащихся, отобранных методом
случайного отбора из 7 разных школ.
Результаты двукратного выполнения работы
запишем в форме таблицы (см. табл. 5).
В
соответствии с целями эксперимента
формулируем нулевую гипотезу следующим
образом: Н 0
-
изучение математики не способствует
формированию изучаемого приема мышления.
Тогда альтернативная гипотеза будет иметь
вид: Н 1
- изучение математики
способствует овладению этим приемом
мышления.
Таблица 5.
Согласно
данным табл. 5, значение статистики Т=15 -
число разностей со знаком «+». Из 35 пар 12
имеют знак «0»; значит,
n
=
35-12
= 23.
По
таблице Приложения 2 для
n
=23 и уровня значимости 0,025
находим критическое значение статистики
критерия, равное 16. Следовательно, верно
неравенство Т Поэтому
в соответствии с правилом принятия
решений приходится сделать вывод о том, что
полученные результаты не дают достаточных
оснований для отклонения нулевой гипотезы,
т. е. мы не располагаем достаточными
основаниями для отклонения утверждения о
том, что изучение математики само по себе не
способствует овладению выделенным
приемом мышления.
Критерий χ 2
(хи-квадрат) применяется для сравнения
распределений объектов двух совокупностей
на основе измерений по шкале наименований в
двух независимых
выборках.
Предположим,
что состояние изучаемого свойства (например,
выполнение определенного задания)
измеряется у каждого объекта по шкале
наименований, имеющей только две
взаимоисключающие категории (например:
выполнено верно - выполнено неверно). По
результатам измерения состояния
изучаемого свойства у объектов двух
выборок составляется четырехклеточная
таблица 2X2. (см. табл. 6).
Таблица 6. В этой таблице О
Тогда на основе
данных таблицы 2X2 (см. табл. 6) можно
проверить нулевую гипотезу о равенстве
вероятностей попадания объектов первой и
второй совокупностей в первою (вторую)
категорию шкалы измерения проверяемого
свойства, например гипотезу о равенстве
вероятностей верного выполнения
некоторого задания учащимися контрольных
и экспериментальных классов.
При проверке
нулевых гипотез не обязательно, чтобы
значения вероятностей р 1
и р 2
были
известны, так как гипотезы только
устанавливают между ними некоторые
соотношения (равенство, больше или меньше).
Для проверки
рассмотренных выше нулевых гипотез по
данным таблицы 2X2 (см. табл. 6) подсчитывается
значение статистики критерия Т
по следующей общей формуле:
где
n
1
,
n
2
- объемывыборок,
N
=
n
1
+
n
2
- общеечисло наблюдений.
Проводится
проверка гипотезы
H
0
:
p
1
£
p
2
- при альтернативе Н 1:
р 1 >р 2 .
Пусть
a
- принятый уровень значимости. Тогда
значение статистики Т,
полученное
на основе экспериментальных данных,
сравнивается с критическим значением
статистики х 1-2
a
,
которое определяется
по таблице
c
2
c
одной степенью свободы (см. Приложение 2) с
учетом выбранного значения
a
.
Если верно неравенство
T
<
x
1-2
a
, то
нулевая гипотеза принимается на уровне
a
.Если данное неравенство не выполняется,
то у нас нет достаточных оснований для
отклонения нулевой гипотезы.
В связи с тем что
замена точного распределения статистики Т
распределением
c
2
c
одной степенью свободы
дает достаточно хорошее приближение только
для больших выборок, применение критерия
ограничено некоторыми условиями.
1)сумма объемов двух выборок меньше 20;
2)хотя бы одна из
абсолютных частот в таблице 2X2,
составленной на основе экспериментальных
данных, меньше 5.
Пример
6.
Проводился
эксперимент, направленный на выявление
лучшего из учебников, написанных двумя
авторскими коллективами в соответствии с
целями обучения геометрии и содержанием
программы
IX
класса. Для
проведения эксперимента методом
случайного отбора были выбраны два района,
большинство школ которых относились по
расположению к сельским. Учащиеся первого
района (20 классов) обучались по учебнику №
1, учащиеся второго района (15 классов) обучались
по учебнику №2.
Рассмотрим
методику сравнения ответов учителей
экспериментальных школ двух районов па
один из вопросов анкеты: «Доступен ли
учебник в целом для самостоятельного
чтения и помогает ли он усвоить материал,
который учитель не объяснял в классе (Ответ:да - нет.)
Отношение
учителей к изучаемому свойству учебников
измерено по шкале наименований, имеющей две
категории: да, нет. Обе выборки учителей
случайные и независимые.
Ответы 20
учителей первого района и 15 учителей
второго района распределим на две
категории и запишем в форме таблицы 2Х2 (табл.
5).
Таблица 7.
Все значения в
табл. 7 не меньше 5, поэтому в соответствии с
условиями использования критерия
c
2
подсчет статистики критерия производится
по формуле (9).
По таблице из
приложения 2
для
одной степени свободы (v
=
l
) и уровня значимости
a
=0,05
найдем х 1-
a
а
=Т критич = 3,84.
Отсюда верно неравенство Т наблюд <Т критич
(1,86<3,84). Согласно правилу принятия решений
для критерия
c
2
,
полученный результат не дает достаточных
оснований для отклонения нулевой гипотезы,
т. е. результаты проведенного опроса
учителей двух экспериментальных районов не
дают достаточных оснований для отклонения
предположения об одинаковой доступности
учебников №
1
и 2 для самостоятельного чтения
учащимися.
Применение
критерия хи-квадрат возможно и в том случае,
когда объекты двух выборок из двух
совокупностей по состоянию изучаемого
свойства распределяются более чем на две
категории. Например, учащиеся
экспериментальных и контрольных классов
распределяются на четыре категории в
соответствии с отметками (в баллах: 2, 3, 4, 5),
полученными учащимися за выполнение
некоторой контрольной работы.
Результаты
измерения состояния изучаемого свойства у
объектов каждой выборки распределяются на
С
категорий. На
основе этих данных составляется таблица 2ХС,
в которой два ряда (по числу
рассматриваемых совокупностей) и С
колонок (по числу различных категорий
состояния изучаемого свойства, принятых в
исследовании).
Таблица 8.
На основе данных
таблицы 8 можно проверить нулевую гипотезу
о равенстве вероятностей попадания
объектов первой и второй совокупностей в
каждую из
i
(
i
=
l
,
2, ..., С) категорий, т. е.
проверить выполнение всех следующих
равенств: р 11 = р 21 ,
p
12
=
p
22
,
…,
p
1
c
=
p
2
c
.
Возможна, например, проверка гипотезы о
равенстве вероятностей получения отметок «5»,
«4», «3» и «2» за выполнение учащимися
контрольных и экспериментальных классов
некоторого задания.
Для проверки
нулевой гипотезы с помощью критерия
c
2
на основе данных
таблицы 2ХС подсчитывается значение
статистики критерия Т
по следующей формуле:
где п 1
и п 2
- объемы выборок.
Значение Т,
полученное на основе
экспериментальных данных, сравнивается с
критическим значением х 1-
a
,
которое определяется
по таблице
c
2
с
k
=С-1 степенью свободы
с учетом выбранного уровнязначимости
a
.
При выполнении неравенства Т> х 1-
a
а
нулевая гипотеза
отклоняется на уровне а
и принимается альтернативная гипотеза.
Это означает, что распределение объектов
на С
категорий по
состоянию изучаемого свойства различно в
двух рассматриваемых совокупностях.
Пример
7
. Рассмотрим методику
сравнения результатов письменной работы,
проверявшей усвоение одного из разделов
курса учащимися первого и второго районов.
Методом
случайного отбора из учащихся первого
района, писавших работу, была составлена
выборка объемом 50 человек, из учащихся
второго района - выборка объемом 50 человек.
В соответствии со специально
разработанными критериями оценки выполнения
работы каждый ученик мог попасть в одну из
четырех категорий: плохо, посредственно,
хорошо, отлично. Результаты выполнения
работы двумя выборками учащихся
используем для проверки гипотезы о том, что
учебник № 1 способствует лучшему усвоению
проверяемого раздела курса, т. е. учащиеся
первого экспериментального района в средне
будут получать более высокие оценки, чем
учащиеся второго района.
Результаты
выполнения работы учащимися обеих выборок
запишем в виде таблицы 2X4 (табл.
9
).
Таблица 9.
В соответствии с
условиями использования критерия
c
2
подсчет статистики критерия производится
по корректированной формуле (10).
В соответствии с
условиями применения двустороннего
критерия хи-квадрат по таблице из
приложения 2
для
одной степени свободы (k
Грабарь М.И., Краснянская К.А. Применение
математической статистики в
педагогических исследованиях.
Непараметрические методы. М., «Педагогика»,
1977, стр. 54
Грабарь М.И., Краснянская К.А. Применение
математической статистики в
педагогических исследованиях.
Непараметрические методы. М., «Педагогика»,
1977, стр. 57
![]()
![]()
![]()
б)
случай связанных (парных) выборок
 (6)
(6)


6.1.3
F - критерий Фишера
![]()
6.2
Непараметрические критерии
6.2.1
Критерий знаков ( G-критерий)

6.2.2
Критерий χ2 (хи-квадрат)

 (9)
(9)


 (10)
(10)
![]()
Рассмотренный выше метод хорошо работает, если качественный признак, который нас интересует, принимает два значения (тромбоз есть - нет, марсианин зеленый - розовый). Более того, поскольку метод является прямым аналогом критерия Стьюдента, число сравниваемых выборок также должно быть равно двум.
Понятно, что и число значений признака и число выборок может оказаться большим двух. Для анализа таких случаев нужен иной метод аналогичный дисперсионному анализу. С виду этот метод, который мы сейчас изложим, сильно отличается от критерия z, но на самом деле между ними много общего.
Чтоб не ходить далеко за примером начнем с только что разобранной задачи о тромбозе шунтов. Теперь мы будем рассматривать не долю, а число больных с тромбозом. Занесем результаты испытания в таблицу (табл. 5.1). Для каждой из групп укажем число больных с тромбозом и без тромбоза. У нас два признака: препарат (аспирин-плацебо) и тромбоз (есть-нет); в таблице указаны все их возможные сочетания, поэтому такая таблица называется таблицей сопряженности. В данном случае размер таблицы 2x2.
Посмотрим на клетки расположенные, на диагонали идущей из верхнего левого в нижний правый угол. Числа в них заметно больше чисел в других клетках таблицы. Это наводит на мысль о связи между приемом аспирина и риском тромбоза.
Теперь взглянем на табл. 5.2. Это таблица ожидаемых чисел, которые мы получили бы, если бы аспирин не влиял на риск тромбоза. Как рассчитать ожидаемые числа, мы разберем чуть ниже, а пока обратим внимание на внешние особенности таблицы. Кроме немного пугающих дробных чисел в клетках можно заметить еще одно отличие от табл. 5.1 - это суммарные данные по группам в правом столбце и по тромбозам - в нижней строке. В правом нижнем углу - общее число больных в испытании. Об-
ратите внимание, что, хотя числа в клетках на рис. 5.1 и 5.2 разные, суммы по строкам и по столбцам одинаковы.
Как же рассчитать ожидаемые числа? Плацебо получали 25 человек, аспирин - 19. Тромбоз шунта произошел у 24 из 44 обследованных, то есть в 54,55% случаев не произошел - у 20 из 44, то есть в 45,45% случаев. Примем нулевую гипотезу о том, что аспирин не влияет на риск тромбоза. Тогда тромбоз должен с равной частотой 54,55% наблюдаться в группах плацебо и аспирина. Рассчитав, сколько составляет 54,55% от 25 и 19, получим соответственно 13,64 и 10,36. Это и есть ожидаемые числа больных с тромбозом в группах плацебо и аспирина. Таким же образом можно получить ожидаемые числа больных без тромбоза в группе плацебо - 45,45% от 25, то есть 11,36 в группе аспирина - 45,45% от 19, то есть 8,64. Обратите внимание, что ожидаемые числа рассчитываются до второго знака после запятой - такая точность понадобится при дальнейших вычислениях.
Сравним табл. 5.1 и 5.2. Числа в клетках довольно сильно различаются. Следовательно, реальная картина отличается от той, которая наблюдалась бы, если бы аспирин не оказывал влияния на риск тромбоза. Теперь осталось построить критерий, который бы характеризовал эти различия одним числом, и затем найти его критическое значение, - то есть поступить, так как в случае критериев F, t или z.
Однако сначала вспомним еще один уже знакомый нам при-
мер - работу Конахана по сравнению галотана и морфина, а именно ту часть, где сравнивалась операционная летальность. Соответствующие данные приведены в табл. 5.3. Форма таблицы такая же, что и табл. 5.1. В свою очередь табл. 5.4 подобно табл. 5.2 содержит ожидаемые числа, то есть числа, вычисленные исходя из предположения, что летальность не зависит от анестетика. Из всех 128 оперированных в живых осталось 110, то есть 85,94%. Если бы выбор анестезии не оказывал влияния на летальность то в обеих группах доля выживших была бы такой же и число выживших составило бы в группе галотана - 85,94% от 61, то есть 52,42 в группе морфина - 85,94% от 67, то есть 57,58. Таким же образом можно получить и ожидаемые числа умерших. Сравним таблицы 5.3 и 5.4. В отличие от предыдущего примера, различия между ожидаемыми и наблюдаемыми значениями очень малы. Как мы выяснили раньше, различий в летальности нет. Похоже мы на правильном пути.
Критерии х2 для таблицы 2x2
Критерий х2 (читается «хи-квадрат») не требует никаких предположений относительно параметров совокупности, из которой извлечены выборки, - это первый из непараметрических критериев, с которым мы знакомимся. Займемся его построением. Во-первых, как и всегда, критерий должен давать одно число,
которое служило бы мерой отличия наблюдаемых данных от ожидаемых, то есть в данном случае различия между таблицей наблюдаемых и ожидаемых чисел. Во-вторых критерий должен учитывать, что различие, скажем, в одного больного имеет большее значение при малом ожидаемом числе, чем при большом.
Определим критерий х2 следующим образом:
где О - наблюдаемое число в клетке таблицы сопряженности, Е - ожидаемое число в той же клетке. Суммирование проводится по всем клеткам таблицы. Как видно из формулы, чем больше разница наблюдаемого и ожидаемого числа, тем больший вклад вносит клетка в величину %2. При этом клетки с малым ожидаемым числом вносят больший вклад. Таким образом, критерий удовлетворяет обоим требованиям - во-первых, измеряет различия и, во-вторых, учитывает их величину относительно ожидаемых чисел.
Применим критерии х2 к данным по тромбозам шунта. В табл. 5.1 приведены наблюдаемые числа, а в табл. 5.2 - ожидаемые.
![]()
ло и значение z, полученное по тем же данным. Можно показать, что для таблиц сопряженности размером 2x2 выполняется равенство X2 = z2.
Критическое значение %2 можно найти хорошо знакомым нам способом. На рис. 5.7 показано распределение возможных значений X2 для таблиц сопряженности размером 2x2 для случая, когда между изучаемыми признаками нет никакой связи. Величина X2 превышает 3,84 только в 5% случаев. Таким образом, 3,84 - критическое значение для 5% уровня значимости. В примере с тромбозом шунта мы получили значение 7,10, поэтому мы отклоняем гипотезу об отсутствии связи между приемом аспирина и образованием тромбов. Напротив, данные из табл. 5.3 хорошо согласуются с гипотезой об одинаковом влиянии галотана и морфина на послеоперационный уровень смертности.
Разумеется, как и все критерии значимости, х2 даёт вероятностную оценку истинности той или иной гипотезы. На самом деле аспирин может и не оказывать влияния на риск тромбоза. На самом деле галотан и морфин могут по-разному влиять на операционную летальность. Но, как показал критерий, и то и другое маловероятно.
Применение критерия х2 правомерно, если ожидаемое число в любой из клеток больше или равно 5. Это условие аналогично условию применимости критерия z.
Критическое значение %2 зависит от размеров таблицы сопряженности, то есть от числа сравниваемых методов лечения (строк таблицы) и числа возможных исходов (столбцов таблицы). Размер таблицы выражается числом степеней свободы v:
V = (r - 1)(с - 1),
где r - число строк, а с - число столбцов. Для таблиц размером 2x2 имеем v = (2 - l)(2 - l) = l. Критические значения %2 для разных v приведены в табл. 5.7.
Приведенная ранее формула для х2 в случае таблицы 2x2 (то есть при 1 степени свободы) дает несколько завышенные значения (сходная ситуация была с критерием z). Это вызвано тем, что теоретическое распределение х2 непрерывно, тогда как набор вычисленных значений х2 дискретен. На практике это приведет к тому, что нулевая гипотеза будет отвергаться слишком часто. Чтобы компенсировать этот эффект, в формулу вводят поправку Йеитса:(1 O - E - -
Заметим, поправка Йеитса применяется только при v = 1, то есть для таблиц 2x2.
Применим поправку Йеитса к изучению связи между приемом аспирина и тромбозами шунта (табл. 5.1 и 5.2):
Как вы помните, без поправки Йейтса значение %2 равнялось 7,10. Исправленное значение %2 оказалось меньше 6,635 - критического значения для 1% уровня значимости, но по-прежнему превосходит 5,024 - критическое значение для 2,5% уровня значимости.
Критерий х2 для произвольной таблицы сопряженности
Теперь рассмотрим случай, когда таблица сопряженности имеет число строк или столбцов, большее двух. Обратите внимание, что критерий z в таких случаях неприменим.
В гл. 3 мы показали, что занятия бегом уменьшают число менструаций*. Побуждают ли эти изменения обращаться к врачу? В табл. 5.5 приведены результаты опроса участниц исследования. Подтверждают ли эти данные гипотезу о том, что занятия бегом не влияют на вероятность обращения к врачу по поводу нерегулярности менструации?
Из 165 обследованных женщин 69 (то есть 42%) обратились к врачу, остальные 96 (то есть 58%) к врачу не обращались. Если
* При этом мы для простоты вычислений размеры всех трех групп - контрольной, физкультурниц и спортсменок - полагали одинаковыми. Теперь мы воспользуемся настоящими данными.
занятия бегом не влияют на вероятность обращения к врачу, то в каждой из групп к врачу должно было обратиться 42% женщин. В табл. 5.6 приведены соответствующие ожидаемые значения. Сильно ли отличаются от них реальные данные?
Для ответа на этот вопрос вычислим %2:
(14 - 22,58)2 (40 - 31,42)2 (9 - 9,62)2
22,58 31,42 9,62
(14 - 13,38)2 (46 - 36,80)2 (42 - 51,20)2
13,38 36,80 51,20
Число строк таблицы сопряженности равно трем, столбцов - двум, поэтому число степеней свободы v = (3 - 1)(2 - 1) = 2. Если гипотеза об отсутствии межгрупповых различий верна, то, как видно из табл. 5.7 значение %2 превзойдет 9,21 не более чем в 1% случаев. Полученное значение больше. Тем самым, при уровне значимости 0,01 можно отклонить гипотезу об отсутствии связи между бегом и обращениями к врачу по поводу менструации. Однако, выяснив, что связь существует мы, тем не менее, не сможем указать какая (какие) именно группы отличаются от остальных.
Итак, мы познакомились с критерием %2. Вот порядок его применения.
Постройте по имеющимся данным таблицу сопряженности.
Подсчитайте число объектов в каждой строке и в каждом столбце и найдите, какую долю от общего числа объектов составляют эти величины.
Зная эти доли, подсчитайте с точностью до двух знаков после запятой ожидаемые числа - количество объектов, которое
попало бы в каждую клетку таблицы, если бы связь между строками и столбцами отсутствовала
Найдите величину, характеризующую различия наблюдаемых и ожидаемых значений. Если таблица сопряженности имеет размер 2x2, примените поправку Йеитса
Вычислите число степеней свободы, выберите уровень значимости и по табл. 5.7, определите критическое значение %2. Сравните его с полученным для вашей таблицы.
Как вы помните, для таблиц сопряженности размером 2x2 критерий х2 применим только в случае, когда все ожидаемые числа больше 5. Как обстоит дело с таблицами большего размера? В этом случае критерии %2 применим, если все ожидаемые числа не меньше 1 и доля клеток с ожидаемыми числами меньше 5 не превышает 20%. При невыполнении этих условии критерии х2 может дать ложные результаты. В таком случае можно собрать дополнительные данные, однако это не всегда осуществимо. Есть и более простой путь - объединить несколько строк или столбцов. Ниже мы покажем, как это сделать.
Преобразование таблиц сопряженности
В предыдущем разделе мы установили существование связи между занятием бегом и обращениями к врачу по поводу менструаций или, что, то же самое, существование различий между группами по частоте обращения к врачу. Однако мы не могли определить, какие именно группы отличаются друг от друга, а какие нет. С похожей ситуацией мы сталкивались в дисперсионном анализе. При сравнении нескольких групп дисперсионный анализ позволяет обнаружить сам факт существования различий, но не указывает выделяющиеся группы. Последнее позволяют сделать процедуры множественного сравнения, о которых мы говорили в гл. 4. Нечто похожее можно проделать и с таблицами сопряженности.
Глядя на табл. 5.5, можно предположить, что физкультурницы и спортсменки обращались к врачу чаще, чем женщины из контрольной группы. Различие между физкультурницами и спортсменками кажется незначительным.
Проверим гипотезу о том, что физкультурницы и спортсмен-
| V | 0,50 | 0,25 | 0,10 | 0,05 | 0,025 | 0,01 | 0,005 | 0,001 |
| 41 | 40,335 | 46,692 | 52,949 | 56,942 | 60,561 | 64,950 | 68,053 | 74,745 |
| 42 | 41,335 | 47,766 | 54,090 | 58,124 | 61,777 | 66,206 | 69,336 | 76,084 |
| 43 | 42,335 | 48,840 | 55,230 | 59,304 | 62,990 | 67,459 | 70,616 | 77,419 |
| 44 | 43,335 | 49,913 | 56,369 | 60,481 | 64,201 | 68,710 | 71,893 | 78,750 |
| 45 | 44,335 | 50,985 | 57,505 | 61,656 | 65,410 | 69,957 | 73,166 | 80,077 |
| 46 | 45,335 | 52,056 | 58,641 | 62,830 | 66,617 | 71,201 | 74,437 | 81,400 |
| 47 | 46,335 | 53,127 | 59,774 | 64,001 | 67,821 | 72,443 | 75,704 | 82,720 |
| 48 | 47,335 | 54,196 | 60,907 | 65,171 | 69,023 | 73,683 | 76,969 | 84,037 |
| 49 | 48,335 | 55,265 | 62,038 | 66,339 | 70,222 | 74,919 | 78,231 | 85,351 |
| 50 | 49,335 | 56,334 | 63,167 | 67,505 | 71,420 | 76,154 | 79,490 | 86,661 |
| Уровень значимости |
| J. H. Zar, Biostatistical Analysis, 2d ed, Prentice-Hall, Englewood Cliffs, N.J., 1984. |
ки обращаются к врачу одинаково часто. Для этого выделим из исходной таблицы подтаблицу, содержащую данные по двум этим группам. В табл. 5.8 приведены наблюдаемые и ожидаемые числа; они довольно близки.
Статистический критерий
Правило, по которому гипотеза Я 0 отвергается или принимается, называется статистическим критерием. В названии критерия, как правило, содержится буква, которой обозначается специально составленная характеристика из п. 2 алгоритма проверки статистической гипотезы (см. п. 4.1), рассчитываемая в критерии. В условиях данного алгоритма критерий назывался бы «в -критерий».
При проверке статистических гипотез возможны два типа ошибок:
- - ошибка первого рода (можно отвергнуть гипотезу Я 0 , когда она на самом деле верна);
- - ошибка второго рода (можно принять гипотезу Я 0 , когда она на самом деле не верна).
Вероятность а допустить ошибку первого рода называется уровнем значимости критерия.
Если за р обозначить вероятность допустить ошибку второго рода, то (l - р) - вероятность не допустить ошибку второго рода, которая называется мощностью критерия.
Критерий согласия х 2 Пирсона
Существует несколько типов статистических гипотез:
- - о законе распределения;
- - однородности выборок;
- - численных значениях параметров распределения и т.д.
Мы будем рассматривать гипотезу о законе распределения на примере критерия согласия х 2 Пирсона.
Критерием согласия называют статистический критерий проверки нулевой гипотезы о предполагаемом законе неизвестного распределения.
В основе критерия согласия Пирсона лежит сравнение эмпирических (наблюдаемых) и теоретических частот наблюдений, вычисленных в предположении определенного закона распределения. Гипотеза # 0 здесь формулируется так: по исследуемому признаку генеральная совокупность распределена нормально.
Алгоритм проверки статистической гипотезы # 0 для критерия х 1 Пирсона:
- 1) выдвигаем гипотезу Я 0 - по исследуемому признаку генеральная совокупность распределена нормально;
- 2) вычисляем выборочную среднюю и выборочное среднее квадратическое отклонение о в;
3) по имеющейся выборке объема п рассчитываем специально составленную характеристику ,
где: я, - эмпирические частоты,
 - теоретические частоты,
- теоретические частоты,
п - объем выборки,
h - величина интервала (разность между двумя соседними вариантами),
Нормализованные значения наблюдаемого признака,
![]() - табличная функция. Также теоретические частоты
- табличная функция. Также теоретические частоты
могут быть вычислены с помощью стандартной функции MS Excel НОРМРАСП по формуле ;
4) по выборочному распределению определяем критическое значение специально составленной характеристики xl P
5) при гипотеза # 0 отвергается, при гипотеза # 0 принимается.
Пример. Рассмотрим признак X - величину показателей тестирования осужденных в одной из исправительных колоний по некоторой психологической характеристике, представленный в виде вариационного ряда:
На уровне значимости 0,05 проверить гипотезу о нормальном распределении генеральной совокупности.
1. На основе эмпирического распределения можно выдвинуть гипотезу Н 0 : по исследуемому признаку «величина показателя тестирования по данной психологической характеристике» генеральная совокупность осу-
жденных распределена нормально. Альтернативная гипотеза 1: по исследуемому признаку «величина показателя тестирования по данной психологической характеристике» генеральная совокупность осужденных не распределена нормально.
2. Вычислим числовые выборочные характеристики:

|
Интервалы |
х г щ |
х} щ |
 |
||||
3. Вычислим специально составленную характеристику j 2 . Для этого в предпоследнем столбце предыдущей таблицы найдем теоретические частоты по формуле , а в последнем столбце
проведем расчет характеристики % 2 . Получаем х 2 = 0,185.
Для наглядности построим полигон эмпирического распределения и нормальную кривую по теоретическим частотам (рис. 6).

Рис. 6.
4. Определим число степеней свободы s : к = 5, т = 2, s = 5-2-1 = 2.
По таблице или с помощью стандартной функции MS Excel «ХИ20БР» для числа степеней свободы 5 = 2 и уровня значимости а = 0,05 найдем критическое значение критерия xl P . =5,99. Для уровня значимости а = 0,01 критическое значение критерия х%. = 9,2.
5. Наблюдаемое значение критерия х =0,185 меньше всех найденных значений Хк Р.-> поэтому гипотеза Я 0 принимается на обоих уровнях значимости. Расхождение эмпирических и теоретических частот незначимое. Следовательно, данные наблюдений согласуются с гипотезой о нормальном распределении генеральной совокупности. Таким образом, по исследуемому признаку «величина показателя тестирования по данной психологической характеристике» генеральная совокупность осужденных распределена нормально.
- 1. Корячко А.В., Куличенко А.Г. Высшая математика и математические методы в психологии: руководство к практическим занятиям для слушателей психологического факультета. Рязань, 1994.
- 2. Наследов А.Д. Математические методы психологического исследования. Анализ и интерпретация данных: Учеб, пособие. СПб., 2008.
- 3. Сидоренко Е.В. Методы математической обработки в психологии. СПб., 2010.
- 4. Сошникова Л.А. и др. Многомерный статистический анализ в экономике: Учеб, пособие для вузов. М., 1999.
- 5. Суходольский Е.В. Математические методы в психологии. Харьков, 2004.
- 6. Шмойлова Р.А., Минашкин В.Е., Садовникова Н.А. Практикум по теории статистики: Учеб, пособие. М., 2009.
- Гмурман В.Е. Теория вероятностей и математическая статистика. С. 465.
Критерий χ 2 Пирсона – это непараметрический метод, который позволяет оценить значимость различий между фактическим (выявленным в результате исследования) количеством исходов или качественных характеристик выборки, попадающих в каждую категорию, и теоретическим количеством, которое можно ожидать в изучаемых группах при справедливости нулевой гипотезы. Выражаясь проще, метод позволяет оценить статистическую значимость различий двух или нескольких относительных показателей (частот, долей).
1. История разработки критерия χ 2
Критерий хи-квадрат для анализа таблиц сопряженности был разработан и предложен в 1900 году английским математиком, статистиком, биологом и философом, основателем математической статистики и одним из основоположников биометрики Карлом Пирсоном (1857-1936).
2. Для чего используется критерий χ 2 Пирсона?
Критерий хи-квадрат может применяться при анализе таблиц сопряженности , содержащих сведения о частоте исходов в зависимости от наличия фактора риска. Например, четырехпольная таблица сопряженности выглядит следующим образом:
| Исход есть (1) | Исхода нет (0) | Всего | |
| Фактор риска есть (1) | A | B | A + B |
| Фактор риска отсутствует (0) | C | D | C + D |
| Всего | A + C | B + D | A + B + C + D |
Как заполнить такую таблицу сопряженности? Рассмотрим небольшой пример.
Проводится исследование влияния курения на риск развития артериальной гипертонии. Для этого были отобраны две группы исследуемых - в первую вошли 70 человек, ежедневно выкуривающих не менее 1 пачки сигарет, во вторую - 80 некурящих такого же возраста. В первой группе у 40 человек отмечалось повышенное артериальное давление. Во второй - артериальная гипертония наблюдалась у 32 человек. Соответственно, нормальное артериальное давление в группе курильщиков было у 30 человек (70 - 40 = 30) а в группе некурящих - у 48 (80 - 32 = 48).
Заполняем исходными данными четырехпольную таблицу сопряженности:
В полученной таблице сопряженности каждая строчка соответствует определенной группе исследуемых. Столбцы - показывают число лиц с артериальной гипертонией или с нормальным артериальным давлением.
Задача, которая ставится перед исследователем: имеются ли статистически значимые различия между частотой лиц с артериальным давлением среди курящих и некурящих? Ответить на этот вопрос можно, рассчитав критерий хи-квадрат Пирсона и сравнив получившееся значение с критическим.
3. Условия и ограничения применения критерия хи-квадрат Пирсона
- Сопоставляемые показатели должны быть измерены в номинальной шкале (например, пол пациента - мужской или женский) или в порядковой (например, степень артериальной гипертензии, принимающая значения от 0 до 3).
- Данный метод позволяет проводить анализ не только четырехпольных таблиц, когда и фактор, и исход являются бинарными переменными, то есть имеют только два возможных значения (например, мужской или женский пол, наличие или отсутствие определенного заболевания в анамнезе...). Критерий хи-квадрат Пирсона может применяться и в случае анализа многопольных таблиц, когда фактор и (или) исход принимают три и более значений.
- Сопоставляемые группы должны быть независимыми, то есть критерий хи-квадрат не должен применяться при сравнении наблюдений "до-"после". В этих случаях проводится тест Мак-Немара (при сравнении двух связанных совокупностей) или рассчитывается Q-критерий Кохрена (в случае сравнения трех и более групп).
- При анализе четырехпольных таблиц ожидаемые значения в каждой из ячеек должны быть не менее 10. В том случае, если хотя бы в одной ячейке ожидаемое явление принимает значение от 5 до 9, критерий хи-квадрат должен рассчитываться с поправкой Йейтса . Если хотя бы в одной ячейке ожидаемое явление меньше 5, то для анализа должен использоваться точный критерий Фишера .
- В случае анализа многопольных таблиц ожидаемое число наблюдений не должно принимать значения менее 5 более чем в 20% ячеек.
4. Как рассчитать критерий хи-квадрат Пирсона?
Для расчета критерия хи-квадрат необходимо:

Данный алгоритм применим как для четырехпольных, так и для многопольных таблиц.
5. Как интерпретировать значение критерия хи-квадрат Пирсона?
В том случае, если полученное значение критерия χ 2 больше критического, делаем вывод о наличии статистической взаимосвязи между изучаемым фактором риска и исходом при соответствующем уровне значимости.
6. Пример расчета критерия хи-квадрат Пирсона
Определим статистическую значимость влияния фактора курения на частоту случаев артериальной гипертонии по рассмотренной выше таблице:
- Рассчитываем ожидаемые значения для каждой ячейки:
- Находим значение критерия хи-квадрат Пирсона:
χ 2 = (40-33.6) 2 /33.6 + (30-36.4) 2 /36.4 + (32-38.4) 2 /38.4 + (48-41.6) 2 /41.6 = 4.396.
- Число степеней свободы f = (2-1)*(2-1) = 1. Находим по таблице критическое значение критерия хи-квадрат Пирсона, которое при уровне значимости p=0.05 и числе степеней свободы 1 составляет 3.841.
- Сравниваем полученное значение критерия хи-квадрат с критическим: 4.396 > 3.841, следовательно зависимость частоты случаев артериальной гипертонии от наличия курения - статистически значима. Уровень значимости данной взаимосвязи соответствует p<0.05.
Рассмотрим применение в MS EXCEL критерия хи-квадрат Пирсона для проверки простых гипотез.
После получения экспериментальных данных (т.е. когда имеется некая выборка ) обычно производится выбор закона распределения, наиболее хорошо описывающего случайную величину, представленную данной выборкой . Проверка того, насколько хорошо экспериментальные данные описываются выбранным теоретическим законом распределения, осуществляется с использованием критериев согласия . Нулевой гипотезой , обычно выступает гипотеза о равенстве распределения случайной величины некоторому теоретическому закону.
Сначала рассмотрим применение критерия согласия Пирсона Х 2 (хи-квадрат) в отношении простых гипотез (параметры теоретического распределения считаются известными). Затем - , когда задается только форма распределения, а параметры этого распределения и значение статистики Х 2 оцениваются/рассчитываются на основании одной и той же выборки .
Примечание : В англоязычной литературе процедура применения критерия согласия Пирсона Х 2 имеет название The chi-square goodness of fit test .
Напомним процедуру проверки гипотез:
- на основе выборки вычисляется значение статистики , которая соответствует типу проверяемой гипотезы. Например, для используется t -статистика (если не известно);
- при условии истинности нулевой гипотезы , распределение этой статистики известно и может быть использовано для вычисления вероятностей (например, для t -статистики это );
- вычисленное на основе выборки значение статистики сравнивается с критическим для заданного значением ();
- нулевую гипотезу отвергают, если значение статистики больше критического (или если вероятность получить это значение статистики () меньше уровня значимости , что является эквивалентным подходом).
Проведем проверку гипотез для различных распределений.
Дискретный случай
Предположим, что два человека играют в кости. У каждого игрока свой набор костей. Игроки по очереди кидают сразу по 3 кубика. Каждый раунд выигрывает тот, кто выкинет за раз больше шестерок. Результаты записываются. У одного из игроков после 100 раундов возникло подозрение, что кости его соперника – несимметричные, т.к. тот часто выигрывает (часто выбрасывает шестерки). Он решил проанализировать насколько вероятно такое количество исходов противника.
Примечание : Т.к. кубиков 3, то за раз можно выкинуть 0; 1; 2 или 3 шестерки, т.е. случайная величина может принимать 4 значения.
Из теории вероятности нам известно, что если кубики симметричные, то вероятность выпадения шестерок подчиняется . Поэтому, после 100 раундов частоты выпадения шестерок могут быть вычислены с помощью формулы
=БИНОМ.РАСП(A7;3;1/6;ЛОЖЬ)*100
В формуле предполагается, что в ячейке А7 содержится соответствующее количество выпавших шестерок в одном раунде.
Примечание : Расчеты приведены в файле примера на листе Дискретное .
Для сравнения наблюденных (Observed) и теоретических частот (Expected) удобно пользоваться .

При значительном отклонении наблюденных частот от теоретического распределения, нулевая гипотеза о распределении случайной величины по теоретическому закону, должна быть отклонена. Т.е., если игральные кости соперника несимметричны, то наблюденные частоты будут «существенно отличаться» от биномиального распределения .
В нашем случае на первый взгляд частоты достаточно близки и без вычислений сложно сделать однозначный вывод. Применим критерий согласия Пирсона Х 2 , чтобы вместо субъективного высказывания «существенно отличаться», которое можно сделать на основании сравнения гистограмм , использовать математически корректное утверждение.
Используем тот факт, что в силу закона больших чисел наблюденная частота (Observed) с ростом объема выборки n стремится к вероятности, соответствующей теоретическому закону (в нашем случае, биномиальному закону ). В нашем случае объем выборки n равен 100.
Введем тестовую статистику , которую обозначим Х 2:

где O l – это наблюденная частота событий, что случайная величина приняла определенные допустимые значения, E l – это соответствующая теоретическая частота (Expected). L – это количество значений, которые может принимать случайная величина (в нашем случае равна 4).
Как видно из формулы, эта статистика является мерой близости наблюденных частот к теоретическим, т.е. с помощью нее можно оценить «расстояния» между этими частотами. Если сумма этих «расстояний» «слишком велика», то эти частоты «существенно отличаются». Понятно, что если наш кубик симметричный (т.е. применим биномиальный закон ), то вероятность того, что сумма «расстояний» будет «слишком велика» будет малой. Чтобы вычислить эту вероятность нам необходимо знать распределение статистики Х 2 (статистика Х 2 вычислена на основе случайной выборки , поэтому она является случайной величиной и, следовательно, имеет свое распределение вероятностей ).
Из многомерного аналога интегральной теоремы Муавра-Лапласа известно, что при n->∞ наша случайная величина Х 2 асимптотически с L - 1 степенями свободы.
Итак, если вычисленное значение статистики Х 2 (сумма «расстояний» между частотами) будет больше чем некое предельное значение, то у нас будет основание отвергнуть нулевую гипотезу . Как и при проверке параметрических гипотез , предельное значение задается через уровень значимости . Если вероятность того, что статистика Х 2 примет значение меньше или равное вычисленному (p -значение ), будет меньше уровня значимости , то нулевую гипотезу можно отвергнуть.
В нашем случае, значение статистики равно 22,757. Вероятность, что статистика Х 2 примет значение больше или равное 22,757 очень мала (0,000045) и может быть вычислена по формулам
=ХИ2.РАСП.ПХ(22,757;4-1)
или
=ХИ2.ТЕСТ(Observed; Expected)
Примечание : Функция ХИ2.ТЕСТ() специально создана для проверки связи между двумя категориальными переменными (см. ).
Вероятность 0,000045 существенно меньше обычного уровня значимости 0,05. Так что, у игрока есть все основания подозревать своего противника в нечестности (нулевая гипотеза о его честности отвергается).

При применении критерия Х 2 необходимо следить за тем, чтобы объем выборки n был достаточно большой, иначе будет неправомочна аппроксимация распределения статистики Х 2 . Обычно считается, что для этого достаточно, чтобы наблюденные частоты (Observed) были больше 5. Если это не так, то малые частоты объединяются в одно или присоединяются к другим частотам, причем объединенному значению приписывается суммарная вероятность и, соответственно, уменьшается число степеней свободы Х 2 -распределения .
Для того чтобы улучшить качество применения критерия Х 2 (), необходимо уменьшать интервалы разбиения (увеличивать L и, соответственно, увеличивать количество степеней свободы ), однако этому препятствует ограничение на количество попавших в каждый интервал наблюдений (д.б.>5).
Непрерывный случай
Критерий согласия Пирсона Х 2 можно применить так же в случае .
Рассмотрим некую выборку , состоящую из 200 значений. Нулевая гипотеза утверждает, что выборка сделана из .
Примечание : Cлучайные величины в файле примера на листе Непрерывное сгенерированы с помощью формулы =НОРМ.СТ.ОБР(СЛЧИС()) . Поэтому, новые значения выборки генерируются при каждом пересчете листа.
Соответствует ли имеющийся набор данных можно визуально оценить .

Как видно из диаграммы, значения выборки довольно хорошо укладываются вдоль прямой. Однако, как и в для проверки гипотезы применим Критерий согласия Пирсона Х 2 .
Для этого разобьем диапазон изменения случайной величины на интервалы с шагом 0,5 . Вычислим наблюденные и теоретические частоты. Наблюденные частоты вычислим с помощью функции ЧАСТОТА() , а теоретические – с помощью функции НОРМ.СТ.РАСП() .
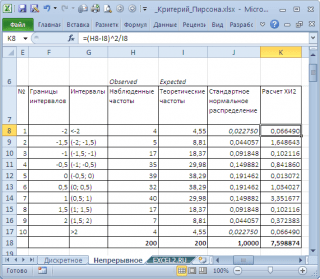
Примечание : Как и для дискретного случая , необходимо следить, чтобы выборка была достаточно большая, а в интервал попадало >5 значений.
Вычислим статистику Х 2 и сравним ее с критическим значением для заданного уровня значимости
(0,05). Т.к. мы разбили диапазон изменения случайной величины на 10 интервалов, то число степеней свободы равно 9. Критическое значение можно вычислить по формуле
=ХИ2.ОБР.ПХ(0,05;9)
или
=ХИ2.ОБР(1-0,05;9)
На диаграмме выше видно, что значение статистики равно 8,19, что существенно выше критического значения – нулевая гипотеза не отвергается.
Ниже приведена , на которой выборка приняла маловероятное значение и на основании критерия согласия Пирсона Х 2 нулевая гипотеза была отклонена (не смотря на то, что случайные значения были сгенерированы с помощью формулы =НОРМ.СТ.ОБР(СЛЧИС()) , обеспечивающей выборку из стандартного нормального распределения ).

Нулевая гипотеза отклонена, хотя визуально данные располагаются довольно близко к прямой линии.
В качестве примера также возьмем выборку из U(-3; 3). В этом случае, даже из графика очевидно, что нулевая гипотеза должна быть отклонена.

Критерий согласия Пирсона Х 2 также подтверждает, что нулевая гипотеза должна быть отклонена.



 Скрытый бан аккаунта в instagram")





